











この記事では、機械学習における「特徴ベクトル」について、その概要や種類、実際の作成例を具体例をもとに解説します。
<目次>
「特徴ベクトル」とは何か
機械学習による分析を行う際に必ず必要となるのが、データを機械が理解できる形で表現することです。例えば、機械学習を使って画像や文章を分析する際、画像や文章そのままでは機械学習のモデルを適用できないため、これを「数値データ」に変換する必要があります。
これは、画像であれば、それぞれのピクセル(画像を構成する最小単位)をグレースケールなどの数値に変換したものになり、文章であれば、文章に含まれる各単語の出現回数などを数値に変換したものとなります。
このように、画像や文章、あるいは顧客の属性など、分析対象が持つ特性を表現した値の列を、機械学習においては「特徴ベクトル」あるいは「特徴量」と呼びます。
また、特徴ベクトルに含まれる個々の数値は、単に「特徴 (feature)」と呼ばれます。
特徴、特徴ベクトル、特徴行列
データを「テーブル」であると考えた場合、個々の分析対象(個々の画像、個々の文章、個々の顧客など)が行、個々の分析対象を表現する特性(各ピクセルのグレースケール値、各単語の出現数、各顧客の年齢・性別・住所など)が列に配置されます。
このとき、各行のことを機械学習ではサンプル(またはデータポイント)と呼びますが、このサンプルの持つ特性を表現した列が、特徴ベクトル(特徴量)に当たります。
また、複数の特徴ベクトルを並べたものは「特徴行列 (feature matrix)」と呼ばれ、行が各サンプル、列がそれぞれのサンプルの特徴ベクトルを表します。
特徴、特徴ベクトル、特徴行列の関係を図示すると以下のようになります。一般的には複数のサンプルを対象に機械学習による分析が行われるため、機械学習を行うための前処理として、この特徴行列が作成されます。

作成:Intelligence In Society
特徴ベクトルの種類
特徴ベクトルには、大きく分けて2つの種類が存在します。
一つは「連続値特徴量 (continuous feature)」です。これは、少数を用いて数値をどこまでも細かく刻むことができる「連続データ」を用いた特徴量で、画像分析における各ピクセルのグレースケール値の他に、重さや長さ、速さ、金額などが該当します。
もう一つは「離散値特徴量 (discrete feature)」で、これは、少数を含まず、整数のみで表される非連続のデータを用いた特徴量です。最も代表的で広く用いられるものに、カテゴリデータを用いた「カテゴリ特徴量」があり、これは性別や都道府県、製品区分、組織区分などが該当します。カテゴリデータは自然な順序や大小関係を持たないことが特徴です。
また、同じ離散値特徴量であるものの順序や大小関係があるものとして、満足度や順位などを表す「順位データ」を用いた特徴量や、西暦や時間などの「間隔データ」を用いた特徴量などが存在します。
連続データ・離散データに関する詳細は、以下のページをご覧ください。
特徴ベクトルの作成例
3つの分析手法
ここでは、実際の特徴ベクトルの作成例として、バラ、アジサイ、ヒマワリの3種類の花について説明した文章を、以下の3つの異なる手法を用いて特徴ベクトルに変換してみます。
文章中に含まれる単語の「出現回数」をカウント
②TF-IDF:
文章に含まれる単語の「重要度」を数値として指標化
③chiVe(チャイブ):
オープンソースの日本語専用単語ベクトル
「②TF-IDF」は、「特定の文章に頻出する一方、他の文章にはあまり現れない単語は、その文章の内容をよく示しているはず」という考えに基づき、特定の文章にだけ頻繁に現れる単語に大きな値(重み)を与える一方、多くの文章に現れる単語には小さな値(重み)を与える手法です。
また、「③chiVe(チャイブ)」は、国立国語学研究所の日本語ウェブコーパスに対して、日本語の形態素解析ライブラリ「Sudachi」 による分かち書きを用いて構築された単語ベクトルです。
分析対象のテキスト
分析対象のテキストには、バラ、アジサイ、ヒマワリの3種類の花に関するwikipediaによる説明文の一部を抜粋したものを使用します。実際に分析する文章は以下です。
バラ:
テキストに対する前処理
テキストデータを特徴ベクトルに変換するためには、分析対象のテキストに対して、クレンジング、単語分割、単語の抽出と除去といった前処理が必要となります。上記の文章に対してこれらの前処理を行うプロセスとその結果については、こちらのページをご覧ください。
特徴ベクトルの作成
上記の前処理を行った結果をもとに、3つの手法で特徴ベクトルを作成したものが以下となります(一部を抜粋)。
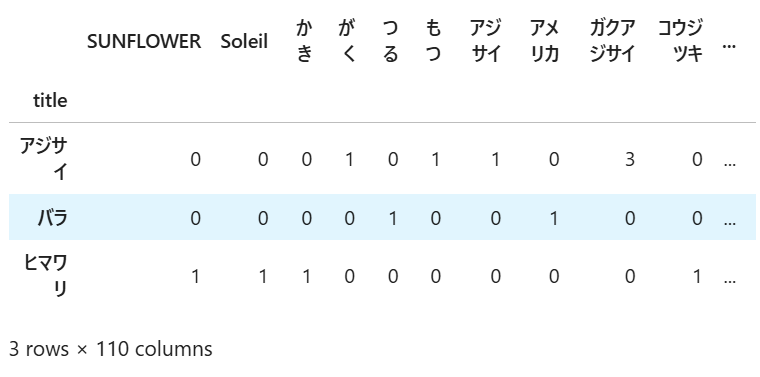
①単語の出現頻度:
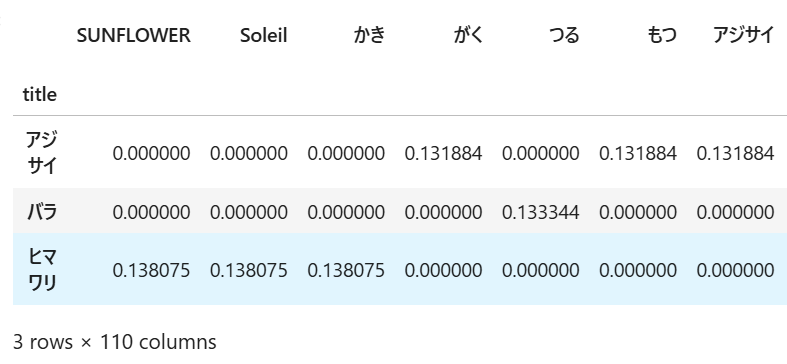
②TF-IDF
③chiVe(チャイブ)
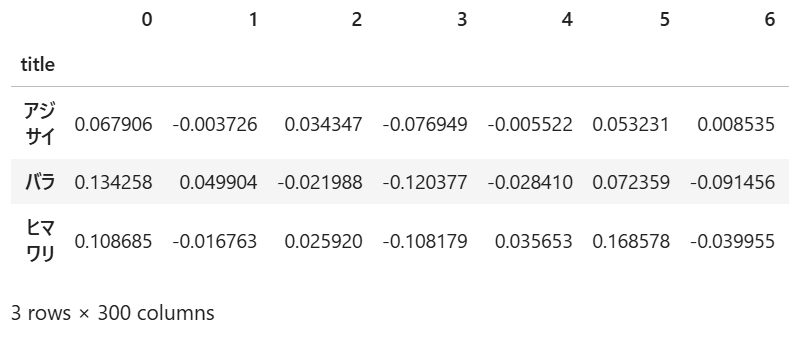
各手法によってそれぞれ異なる特徴ベクトルが作成されていることが分かります。
特に、①単語の出現頻度と②TF-IDFは、同じ「3行×110列」の特徴行列に対して、異なる特徴の値が付与されているのに対し、③chiVeでは、特徴行列の形自体が「3行×300列」と異なるものになっていることが見て取れます。
これは、①単語の出現頻度と②TF-IDFでは、文章に対する前処理を経て抽出された110個の単語に対して、文章ごとにそれぞれの値が付与されているのに対して、③chiVeでは、全ての単語がchiVe内で予め300個の特徴値で表現されており、各文章ごとに、そこに含まれる全ての単語をもとに300個の特徴値の平均を取ったものになっているためです。
ここまで、機械学習における「特徴ベクトル」について、その概要や種類、実際の作成例を解説しました。
当記事に関連するトピックについての詳細は、以下のページをご覧ください。
また、機械学習に関する全ての記事は以下のページからご覧いただけます。
参考文献:
◦河村・久本・真鍋・高岡・内田・岡・浅原 (2020) 「chiVe 2.0:SudachiとNWJCを用いた実用的な日本語単語ベクトルの実現に向けて」『言語処理学会 第26回年次大会 発表論文集』
◦Andreas C. Muller、Sarah Guido (2017)『Pythonではじめる機械学習―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎』O’Reilly Japan
◦scikit-learn “User Guide – 7.2. Feature extraction” https://scikit-learn.org/stable/modules/feature_extraction.html (2026年4月28日最終閲覧)














