











この記事では、テキスト分析において広く用いられる「TF-IDF」について、その意味や算出方法、TF-IDFを用いたテキスト分類の進め方について、具体例をもとに解説します。
<目次>
TF-IDFとは何か
「TF-IDF (Term Frequency-Inverse Document Frequency)」は、テキストデータの分析において、文章に含まれる単語の「重要度」を評価する手法です。文章中の単語が「どの程度情報を持っていそうか」(=その単語の重要度)を数値として指標化することで、これを特徴量とした機械学習の分析などを行うことが可能となります。
TF-IDFでは、「特定の文章に頻出する一方、他の文章にはあまり現れない単語は、その文章の内容をよく示しているはず」という考えに基づき、特定の文章にだけ頻繁に現れる単語に大きな値(重み)を与える一方、多くの文章に現れる単語には小さな値(重み)が与えられます。
例えば、「バラ」と「アジサイ」の2つの花について説明している文章を分類する場合、「花びら」「色」「品種」といった単語はどちらのグループの文章にも登場すると想定される一方、「棘(トゲ)」「梅雨」といった単語は、それぞれ片方のグループにしか登場しない特徴的な単語であると想定されます。
TF-IDFでは、特徴的な単語に大きな重みが与えられることで、この情報に基づいて、新しい文章がどちらの花について説明したものかを分類することなどができるようになります。
TF-IDFの算出方法
TF-IDFは、「用語出現頻度」を意味する「TF (Term Frequency)」と、「逆文書頻度」を意味する「IDF (Inverse Document Frequency)」を掛け合わせることで算出されます。
TFとIDFの具体的な内容は、以下に示す通りです。この2つの指標の掛け合わせにより、ドキュメント(文章など)と単語のセットに対してそれぞれ異なるTF-IDFの値が算出され、データ分析が可能な「特徴ベクトル」に変換されます。
TF (Term Frequency)
TF (Term Frequency:用語出現頻度) は、単一のドキュメント(文章)内における特定の単語の出現頻度を表します。具体的には、以下の計算式によって算出されます。
例えば、バラについて説明する文章の中で、「花」という単語が5回、「棘(トゲ)」という単語が3回、「梅雨」という単語が0回出現し、全単語の総出現回数が50回だったとした場合、この文章における各単語のTFは以下となります。
| 花 | 棘(トゲ) | 梅雨 | |
| TF | 5/50=0.10 | 3/50=0.06 | 0/50=0 |
「花」のように、対象の文章中にその単語が多く含まれているほど、TFの値が大きくなり、その単語に大きな重みが与えられます。
IDF (Inverse Document Frequency)
IDF (Inverse Document Frequency:逆文書頻度) は、全ドキュメント(文章)中における特定の単語の出現頻度の「逆数」を表します。具体的には、以下の計算式によって算出されます。
例えば、様々な花について説明した全30個の文章の中で、「花」という単語が25個の文章、「棘(トゲ)」という単語が5個の文章、「梅雨」という単語が3個の文章で出現した場合、全文章中における各単語のIDFは以下となります。
| 花 | 棘(トゲ) | 梅雨 | |
| IDF | log(30/25)+1≃1.08 | log(30/5)+1≃1.78 | log(30/3)+1= 2.00 |
ほとんどの文章に含まれる「花」に対して、一部の文章のみに含まれる「棘(トゲ)」や「梅雨」といったより珍しい単語ほど、IDFの値が大きくなり、その単語に大きな重みが与えられます。
なお、上記式において「+ 1」が付加されているのは、log(0)によって定義域エラーとなり、TF-IDFの値が算出できない事態を回避することを目的としたものです。
また、TFやTF-IDFが単一のドキュメント(文章)に対するものであるのに対して、IDFは全文章(対象の文章全体)に対するものである点に注意が必要です。
TF-IDFを用いたテキスト分類
TF-IDFを用いたテキスト分類の進め方の具体例を、バラ、アジサイ、ヒマワリの3種類の花について説明した文章に基づく分析をもとに見ていきます。対象のテキストには、これらの花に関するwikipediaによる説明文の一部を抜粋したものを使用します。実際に分析する文章は以下です。
バラ:
また、これらの説明文に加えて、以下の2つのフレーズを考えます。この2つのフレーズは、検索エンジンに対して入力された検索クエリに当たります。
検索クエリ2: 種が食用になる夏に咲く花
これら3つの説明文と2つの検索クエリについてTF-IDFを算出し、それぞれの説明文と検索クエリの間のTF-IDFに基づく類似度を計算することで、検索クエリに対して最も類似度が高い(=検索意図に合致した)花の種類を選択することが、この分析のゴールです。
Bag of Wrodsの作成
TF-IDFを算出するための前処理として、3つの説明文と2つの検索クエリに関するBag of Wrodsを作成します。
Bag of Wrodsの作成には、大きく分けて以下のステップを踏みます。
②文章の単語分割(形態素解析)
③単語の抽出と除去
①データのクレンジング
このステップでは、対象となる文章に対して、空白、改行、感嘆符、各種の記号といった重要ではない要素の除去や、半角と全角の違いような「表記ゆれ」の統一などを行います。
上記の説明文と検索クエリに対してデータクレンジングを実施した結果は以下のようになります。なお以下では、文章を文に分割した上で、各文を行に展開しています。

②文章の単語分割(形態素解析)
クレンジング済みの文章に対して、文章を単語に分割したり、単語の品詞やその基本形を取得する処理を行います。このような処理を日本語の文章に対して行う処理を形態素解析と呼びます。
形態素解析を行った結果は以下のようになります。ここで、「text」は分割された元の単語、「lemma」はその単語の原型、「pos」は単語の品詞、「is_stop」はその単語がストップワード(後述)であるか否か、を表します。
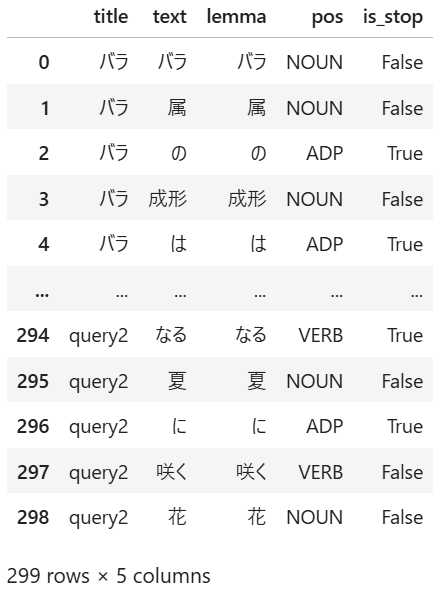
③単語の抽出と除去
形態素解析によって分割された各単語に対して、文章の意味において重要である可能性の高い品詞の抽出と、それ以外の品詞の除去などを行います。
また、「する」「ある」「こと」「とき」など、文書中に非常に多く登場する一方で、意味においての重要性は低い単語である「ストップワード」についても、この段階で除去します。
ここまでのステップを経て、3つの説明文と2つの検索クエリから、以下の112個の単語が抽出されました。
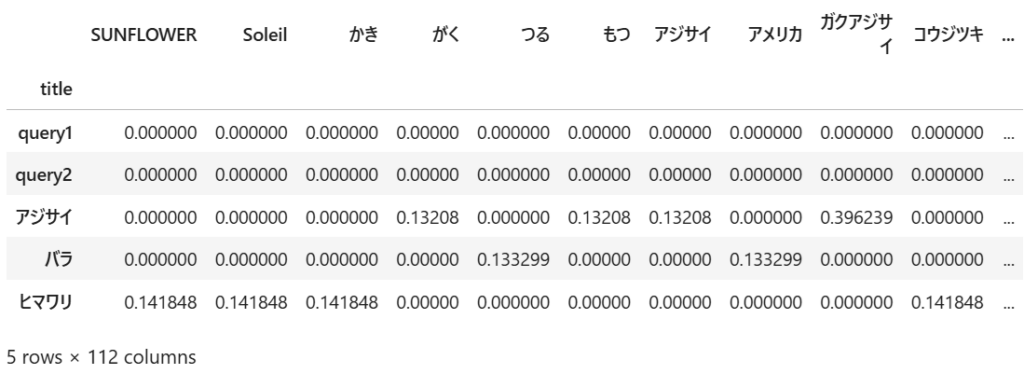
TF-IDFの算出
作成されたBag of Wrodsをもとに、TF-IDFを算出します。結果は、3つの説明文と2つの検索クエリに対して、112個の各単語が持つTF-IDFの値が計算された、5×112のマトリクスとなります。
「title」列が2つの検索クエリと3つの説明文を表し、「SUNFLOWER」以降の列名が抽出された各単語を表しています。対象の文章に登場しない単語は、TF-IDFの値がゼロとなっていることが分かります。
クエリに対する類似度の計算
算出されたTF-IDFをもとに、2つの検索クエリと3つの説明文の類似度を計算することで、検索クエリと最も類似度が高い(=検索意図に合致した)花の種類を選択します。
ここでの類似度の計算には、「コサイン類似度関数」を使用します。コサイン類似度は、テキスト分類においてドキュメント間の類似度を測定するために広く用いられる手法です。2つの特徴ベクトル(XとY)のコサイン類似度は以下によって求められます。
コサイン類似度の計算結果は以下となります。
| 検索クエリ | バラ | アジサイ | ヒマワリ |
| 日本が原産の梅雨に咲く花 | 0.02 | 0.13 | 0.05 |
| 種が食用になる夏に咲く花 | 0.06 | 0.04 | 0.27 |
アジサイを意図した1つ目の検索クエリに対しては、アジサイのコサイン類似度が最も高くなっています。また、ヒマワリを意図した2つ目の検索クエリに対しては、ヒマワリのコサイン類似度が最も高くなっています。
TF-IDFをもとに各種類の花の説明文を特徴ベクトルに変換したことで、検索クエリと適切にマッチングできたことが確認できます。
ここまで、テキスト分析において広く用いられる「TF-IDF」について、その意味や算出方法、TF-IDFを用いたテキスト分類の進め方について解説しました。
当記事に関連するトピックについての詳細は、以下のページをご覧ください。
また、機械学習に関する全ての記事は以下のページからご覧いただけます。
参考文献:
◦Foster Provost, Tom Fawcett (2014) 『戦略的データサイエンス入門―ビジネスに活かすコンセプトとテクニック』O’Reilly Japan
◦Andreas C. Muller、Sarah Guido (2017)『Pythonではじめる機械学習―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎』O’Reilly Japan
◦本橋智光・橋本秀太郎 (2024)『改定新版 前処理大全-SQL/Pandas/Polars実践テクニック-』技術評論社
◦scikit-learn “User Guide – 7.2. Feature extraction” https://scikit-learn.org/stable/modules/feature_extraction.html (2026年4月21日最終閲覧)














