











この記事では、機械学習における評価指標について、「回帰」「二値分類」「多クラス分類」の各ケース別に、代表的な指標とその定義・特徴を解説します。
<目次>
機械学習の代表的タスク:回帰と分類
機械学習や統計分析などデータサイエンスにおける代表的なタスクに「分類」と「回帰」があります。
「分類 (Classification)」が、母集団の構成要素がどのクラスに分類されるかを予測することを指すのに対して、「回帰 (regression)」は、端的には「値の推定」であり、データをもとに目的変数の数値を予測・推定することを指します。
また、「回帰」のうち、「陽性か陰性か」「正例か負例か」といった分類を行うタスクは「二値分類」、3つ以上のクラスへの分類を行うタスクは「多クラス分類(マルチクラス分類)」と呼ばれます。「二値分類」と「多クラス分類」は、さらに以下のような類型へ分類することが可能です。
二値分類:
– 各予測対象が「陽性か陰性か(正例か負例か)」を予測するもの
– 各予測対象が「陽性(正例)である確率」を予測するもの
多クラス分類:
– 「どのクラスに属するか」を予測するもの
– 上記のうち、クラス間に順序関係があるもの
– 「あるクラスに属する確率」を予測するもの
機械学習モデルの評価においては、モデルが何を予測するのかによって適切な評価指標が異なるため、予測対象の性質に応じた評価指標を選択することが重要です。以下では、回帰・二値分類・多クラス分類の各予測モデルについて、ケース別の代表的な評価指標を解説します。
回帰モデルにおける評価指標
実際の値と推定値の差を「誤差」と呼びますが、回帰モデルにおける評価指標は大きく、誤差の大きさに関する評価指標(RMSE、RMSLE、MAE、R2など)と誤差率に関する評価指標(MAPEなど)の2種類に分けることができます。
「誤差の大きさ」に関する評価指標
RMSE (Root Mean Squared Error)
RMSE (Root Mean Squared Error:平均平方二乗誤差)
- 目的変数について実際の値と推定値の各セットにおける「差の二乗」を計算、それらを平均した上で平方根をとることで得られます。値が小さい(実際の値と推定値の誤差が小さい)ほど、精度が高いと評価されます。
- 外れ値の影響を受けやすいという特徴があるため、RMSEを目的関数として機械学習を行う場合には、モデルが外れ値に過剰に適合した学習をしてしまう可能性に注意が必要です。
※各記号は、N:サンプル数、yi:i番目のサンプルの実際の値、yi (ハット):i番目のサンプルの推定値、を表します。
RMSLE (Root Mean Squared Logarithmic Error)
RMSLE (Root Mean Squared Logarithmic Error)
- 「実際の値の対数」と「推定値の対数」の「差の二乗」を計算し、それらを平均した上で平方根をとることで得られます。RMSEとの違いは、実際の値と推定値をそのまま使うのではなく、両者を対数化している点です。
- RMSLEが使用されるケースは、所得分布などのように対象となる変数が裾の長い分布を持っており、そのまま使用すると大きな値の影響が強く出てしまうことが懸念される場合です。
- また、計算式の2乗カッコ内は実際の値と推定値の比率を表現したものとなっていることから、RMSLEは実際の値と推定値の比率を評価対象としたいケースにおいても使用されます。
MAE (Mean Absolute Error)
MAE (Mean Absolute Error:平均絶対誤差)
- 実際の値と推定値の「差の絶対値」の平均によって計算されます。RMSEとの違いは、差を二乗するのではなく、差の絶対値を取る点です。値が小さい(実際の値と推定値の誤差が小さい)ほど、精度が高いと評価されます。
- 誤差を二乗することで外れ値にペナルティを与えるRMSEやMSEと比較し、MAEには外れ値の影響を受けにくいという特徴があります。
R2 (決定係数)
R2 (決定係数)
- 回帰モデルによる推定結果が、実際のデータにどの程度当てはまっているか(回帰モデルの当てはまりの良さ)を表す指標です。回帰モデルが、実際の値に対してどれだけの説明能力を持っているかを0 ~ 1の数値で表現します。
- 「予測値で説明される変動」の「全変動」に対する比率として計算され、回帰モデルの実際のデータに対する説明能力を表します。数値が1に近いほど当てはまりが良く、高い精度の推定を行っていることを意味します。
※y(バー)は、目的変数の実際の値の平均値を表します。
「誤差率」に関する評価指標
MAPE (Mean Absolute Percentage Error)
MAPE (Mean Absolute Percentage Error:平均絶対誤差率)
- 実際の値に対する推定値の誤差の大きさを、実際の値に対する比率(=誤差率)として算出し、全てのサンプルの誤差率の平均を取ってパーセントで表します。値が小さいほど推定の精度が高いと評価されます。
- 実際の値(y)が0であった場合、分母が0となり適切な計算ができないといった問題点があるため、実際の値が0に近い母集団の推定を行う際は、別の評価指標を使うことも合わせて検討する必要があります。
回帰モデルの評価指標に関する詳細は、以下のページをご覧ください。
二値分類モデルにおける評価指標
混同行列 (confusion matrix)
分類タスクの評価指標を定義する際に重要となるのが、混同行列 (confusion matrix)です。混同行列は、予測値と実際の値との関係を以下の4区分に整理した上で、それをマトリクス上に表現したものです。
- TP:真陽性(True Positive) ― 陽性と予測し、その予測が正しい場合
- FP:偽陽性(False Positive) ― 陽性と予測し、その予測が正しくない場合
- TN:真陰性(True Negative) ― 陰性と予測し、その予測が正しい場合
- TP:偽陰性(False Negative) ― 陰性と予測し、その予測が正しくない場合
| 実際の値=陽性 | 実際の値=陰性 | |
| 陽性と予測 |
TP: |
FP: |
| 陰性と予測 |
FN: |
TN: |
以下では、この混同行列の表現を用いて、各評価指標の定義を解説します。
「陽性か陰性か」を予測するケース
正答率 (accuracy)
正答率 (accuracy)
全ての予測のうち、正しい予測の割合を表し、「精度」とも呼ばれます。混同行列の要素を用いた表現では、正しい予測数を全予測数で割ったものとして表されます。正答率はその分かりやすさから広く使用される一方、以下のような問題点があるため、使用においては十分な注意が必要です。
①不均衡なデータにおける評価:
例えばWEB広告のクリック率のように、陽性となる(クリックされる)確率が非常に低い予測対象では、単純に「全て陰性」と予測することで99%以上の非常に高い正答率を出すことができますが、当然このような予測モデルには意味がありません。
②偽陽性と偽陰性の区別:
正答率では偽陽性によるエラーと偽陰性によるエラーが区別されず、それぞれのエラーが同じ重要度として評価されます。しかし現実には、例えば癌検診のように、癌が見過ごされることを意味する「偽陰性」は「偽陽性」よりも深刻であり、より重大な意味を持ちます。
適合率 (precision)・再現率 (recall)
適合率 (precision)・再現率 (recall)
- 「適合率 (precision)」は、陽性であると予測されたものが実際にどのくらい陽性であったかを測定するもので、「陽性的中率 (PPV : positive predictive value)」 とも呼ばれます。
- 適合率とセットで用いられる指標が「再現率 (recall)」です。実際に陽性のサンプルのうち、陽性と予測されたものの割合として表されるもので、「真陽性率」と同じことを意味します。
- 「適合率」は、誤って陽性であると予測してしまうケース(偽陽性)を制限したい場合にその指標として重視されます。一方、「再現率」は、陽性のサンプルを誤って陰性と予測してしまうケース(偽陰性)を避けたい場合に重視されます。適合率と再現率はトレードオフの関係にあります。
F1スコア (F-measure)
F1スコア (F値、F-measure)
- F1スコアは、適合率と再現率の間のトレードオフを考慮し、2つをまとめる指標です。適合率と再現率の調和平均(逆数の平均の逆数)で、適合率と再現率がどの程度バランス良く高い値を取っているかを表します。
- 適合率と再現率の双方を考慮することで、正答率では適切な評価が難しい「偏りのあるデータ」においても、より適切な評価指標となります。
「陽性か陰性か」を予測する二値分類モデルの評価指標に関する詳細は、以下のページをご覧ください。
「陽性である確率」を予測するケース
logloss (交差エントロピー損失)
logloss (交差エントロピー損失)
- loglossは2つの確率関数の差を測る指標で、「交差エントロピー損失 (cross-entropy-loss)」とも呼ばれます。「2つの確率関数」とは、「実際の値が陽性か否か(陽性:yi 、陰性:1-yi )」と、「実際の値を予測する確率(陽性の予測:pi 、陰性の予測:1-pi )」を指します。
- p’ は実際の値を予測している確率を表し、実際の値が陽性の場合はpi 、陰性の場合は1-pi となります。loglossは0~ 無限大の値を取り、値が小さいほど、より正確な確率の予測を行っていると評価されます。
- 実際の値が陽性であるにも関わらず、その確率を低く予測した場合や、逆に陰性であるにも関わらず、高い確率で陽性であると予測した場合にペナルティが与えられ、loglossの値は大きくなります。
| 実際の値(yi ) | 陽性の予測確率(pi ) | -log(p’i ) | |
| 1 | 1 (陽性) | 0.8 | -log(0.8) = 0.223 |
| 2 | 0 (陰性) | 0.3 | -log(0.7) = 0.357 |
| 3 | 1 (陽性) | 0.4 | -log(0.4) = 0.916 |
| 平均 | logloss : 0.499 |
||
PR曲線と平均適合率
PR曲線 (precision-recall curve:適合率-再現率カーブ)
- PR曲線は、実現可能な適合率 (precision)と再現率 (recall)の組み合わせを同時に見るために使用されます。2つの指標の全ての組み合わせを平面上にプロットすることで、特定の1点における評価では把握できなかった、モデルの総体的な性能を確認することができます。
- 下図は、同じデータに対してサポートベクトルマシン (svc) とランダムフォレスト (rf) の2つのモデルで予測を行い、それぞれのPR曲線を重ねて表示したものです。適合率がおおよそ0.5~0.8の領域においては、svcの再現率がrfを上回っておりより優れていますが、再現率が0.5以下または0.8以上の領域においては、逆にrfの再現率がsvcを上回っています。
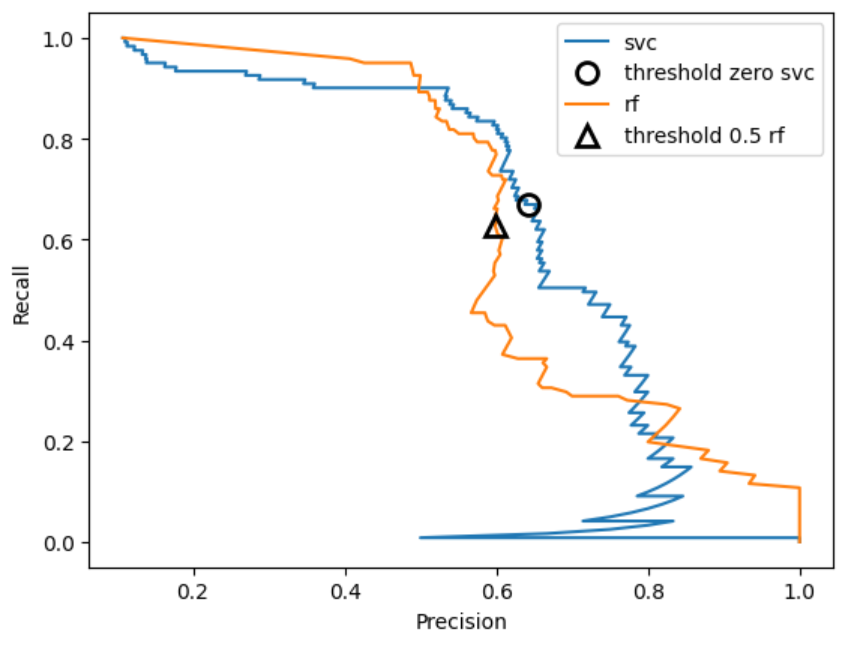
Muller, Guide(2017)をもとに、Intelligence In Society作成
平均適合率 (average precision)
- PR曲線の情報を1つの値で要約する指標の一つで、適合率の(再現率の増加量を重さとする)加重平均で計算されます。平均適合率はPR曲線のカーブの下の領域に該当し、0 (最悪値) ~ 1 (最良値) を取ります。
- 上記2モデルの平均適合率はそれぞれ、svc = 0.663、rf = 0.666 となり、僅かにrfの方がより優れたモデルとして評価されます1。
※Pnは適合率、Rnは再現率を表します。
ROC曲線とAUC
ROC曲線 (Receiver Operating Characteristic Curve)
- 閾値を1から0に動かした際の真陽性率(y軸)と偽陽性率(x軸)の変化を平面上にプロットしたものです。(真陽性率:実際に陽性のサンプルのうち、陽性と予測されたものの割合。偽陽性率:実際は陰性のサンプルのうち、陽性と予測されたものの割合。)
- 利益率の高い潜在顧客を予測するモデルを例にした場合、ROC曲線は、モデルが利益(真陽性率)とコスト(偽陽性率)の間に生み出すトレードオフの関係を示したものと捉えることができます。
- 下図は、先ほどと同じ2つのモデルについて、それぞれのROC曲線を重ねて示したものです。対角に引かれた点線は、ランダムに予測するモデルのROC曲線を示しています。
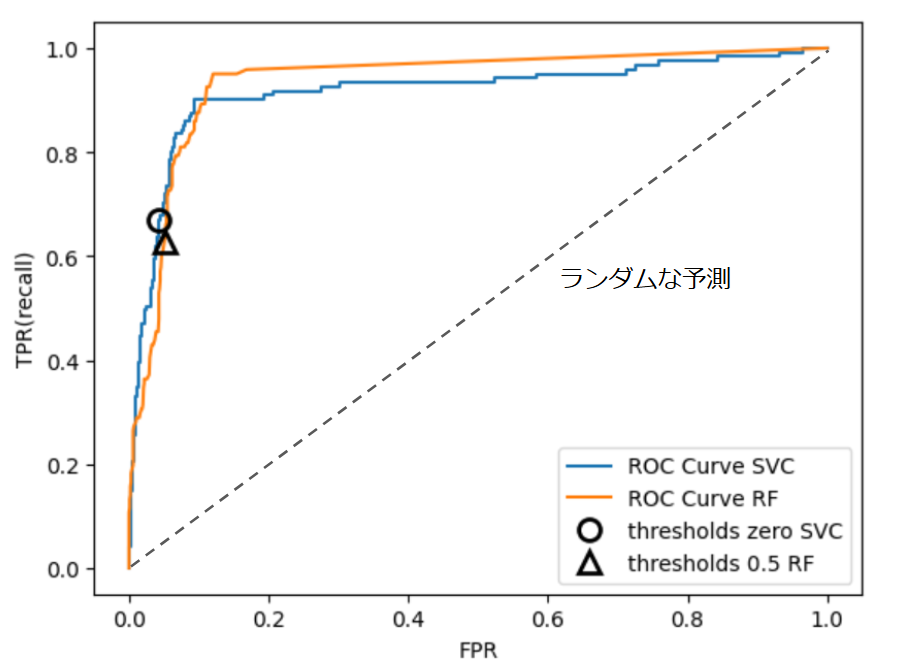
Muller, Guide(2017)をもとに、Intelligence In Society作成
AUC (Area Under the ROC Curve)
- AUCは、ROC曲線が描くカーブの下の領域の面積にあたります。ランダムに選んだ陽性のサンプルに対するモデルの予測値が、同じくランダムに選んだ陰性のサンプルに対するモデルの予測値よりも大きくなる確率と同等です。
- 上記2モデルのAUCは、SVC:0.916、RF:0.937となり、RFの方が優れたモデルと評価されます2。いずれも、ランダムに予測するモデルのAUC (=0.5) と比べて十分高い性能を示しています。
- 陽性のサンプル数と陰性のサンプル数が大きく異なる「偏りのあるデータ」においても、ランダムに予測するモデルのAUCは常に0.5となるため、正答率(精度)などと比べて「偏りのあるデータ」においてより適切な評価指標であると言えます。
「陽性である確率」を予測する二値分類モデルの評価指標に関する詳細は、以下のページをご覧ください。
多クラス分類モデルにおける評価指標
「どのクラスに属するか」を予測するケース
正答率 (multi-class accuracy)
正答率 (multi-class accuracy)
- 多クラス分類における正答率は、クラス分布に偏りが無いデータに適した評価指標です。二値分類タスクにおける正答率を多クラスに拡張したもので、全ての予測(全サンプル数)のうち、正しく予測されたサンプル数の割合によって表されます。
- 正答率はその分かりやすさが大きな強みである一方、クラス分類に偏りのある不均衡なデータにおいては不適切な評価指標となる可能性があります。仮に、0~9の10クラス分類においてクラス「0」が全体の9割を占めている場合、全サンプルを「0」と予測するモデルの正答率は90%となりますが、そのようなモデルには意味がありません。
mean-F1, macro-F1, micro-F1
mean-F1, macro-F1, micro-F1
mean-F1, macro-F1, micro-F1は、不均衡なデータでの使用により適した評価指標です。各サンプルが1つ以上のクラスに属する「マルチラベル分類」においても良く使用されます。
mean-F1:
サンプル単位で計算したF1スコアの平均値です。例えば下表のサンプルNo.1のF1スコアは、(TP=1, TN=0, FP=2, FN=2) で0.33となりますが、これを各サンプルについて算出し平均した0.377が、mean-F1スコアとなります。
macro-F1:
クラス単位で計算したF1スコアの平均値です。例えば下表のクラス1のF1スコアは、(TP=1, TN=0, FP=1, FN=1) で0.5となりますが、これを各クラスについて算出し平均した0.388が、macro-F1スコアとなります。
micro-F1:
サンプル×クラスの全てのペアについて、それぞれ個別に真陽性・真陰性・偽陽性・偽陰性を判別し、その混合行列に基づいて計算したF値です。例えば下表では、3つのサンプル×5クラスで15のペアがあり、全てを分類すると (TP=3, TN=2, FP=5, FN=5) となることから、この混合行列よりmicro-F1スコアが0.375と計算されます。( 2TP/(2TP + FP + FN) = 0.375 )
| サンプルNo | 実際の値 | 予測値 |
| 1 | 1, 2, 5 | 1, 3, 4 |
| 2 | 1, 4, 5 | 2, 5 |
| 3 | 3, 4 | 1, 3, 5 |
クラス間に順序関係があるケース
quadratic weighted kappa
quadratic weighted kappa (QWK)
- 年齢齢区分や年収区分、ECでの商品のレーティングなど、多クラス分類の中でも特にクラス間に順序関係がある場合に使用される評価指標です。
- 「ランダムにクラス分類を行った場合の偶然の一致に比べて、実際の値と予測値の一致度がどのくらい高いか」を評価するコーエンのカッパ係数 (Cohen’s kappa) に対して、「実際の値と予測値の差の二乗」を重み( =w ) として付与したものです。これにより、実際の値から大きく離れた予測値に対してペナルティを課しています。
※poは実際の値と予測値の観測された一致率、peは仮に実際の値と予測値がともにランダムにクラス分類を行ったとした場合に期待される一致率を表します。
「あるクラスに属する確率」を予測するケース
logloss (multi-class logloss)
logloss (multi-class logloss)
- 多クラス分類におけるloglossは、「あるクラスに属する確率」を予測する際の評価指標としてよく用いられます。二値分類におけるloglossを多クラス分類に拡張したもので、実際の値に対する予測確率の対数を取り、符号を反転させたものを、全てのサンプルについて平均したものとして計算されます。
- 0~ 無限大の値を取り、値が小さいほど、より正確な確率の予測を行っていると評価されます。下記例のように、サンプルの実際のクラスに対する確率を低く予測すると、大きなペナルティが与えられ、loglossが大きな値となります。
| 各クラスの予測確率 | |||||
| 実際の値 | 1 | 2 | 3 | 実際の値の予測確率p’i | -log(p’i) |
| 1 | 0.7 | 0.1 | 0.2 | 0.7 | 0.357 |
| 2 | 0.4 | 0.5 | 0.1 | 0.5 | 0.693 |
| 3 | 0.3 | 0.4 | 0.3 | 0.3 | 1.20 |
| 平均 |
logloss: |
||||
多クラス分類モデルの評価指標に関する詳細は、以下のページをご覧ください。
ここまで、機械学習における評価指標について、「回帰」「二値分類」「多クラス分類」の各ケース別に、代表的な指標とその定義・特徴を解説しました。
当記事に関連するトピックについての詳細は、以下のページをご覧ください。
また、機械学習・データ分析一般に関する全ての記事は以下のページからご覧いただけます。
参考文献:
◦scikit-learn “API Reference – sklearn.metrics ” https://scikit-learn.org/stable/modules/generated/sklearn.metrics.html (2026年6月23日最終閲覧)
◦Andreas C. Muller、Sarah Guido (2017)『Pythonではじめる機械学習―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎』O’Reilly Japan
◦門脇大輔,阪田隆司,保坂桂佑,平松雄司 (2019)『Kaggleで勝つデータ分析の技術』, 技術評論社
◦Foster Provost, Tom Fawcett (2014) 『戦略的データサイエンス入門―ビジネスに活かすコンセプトとテクニック』O’Reilly Japan
◦八谷大岳 (2020) 『ゼロからつくるPython機械学習プログラミング入門』講談社
◦金本拓 (2024) 『因果推論ー基礎から機械学習・時系列解析・因果探索を用いた意思決定のアプローチー』, オーム社
◦栗原伸一・丸山敦史 (2017)『統計学図鑑』オーム社
注記:
1, 2. Muller, Guide(2017)より引用
















