











この記事では、「多クラス分類タスク」における代表的な評価指標について、その定義・計算方法や特徴を具体例をもとに解説します。
<目次>
二値分類における評価指標の概要
機会学習などにおいて、母集団の構成要素がどのクラスに分類されるかを予測することを「分類 (Classification)」と呼びますが、そのうち「陽性か陰性か」「正例か負例か」といった分類を行うタスクは「二値分類」と呼ばれます。
一方、「血液型がA型・B型・O型・AB型のうちどれか」「ある花の画像がバラ・アジサイ・ヒマワリのうちどれに当たるか」のように3つ以上のクラスへの分類を行うタスクを「多クラス分類(マルチクラス分類)」と呼びます。
以下では、多クラス分類タスクにおける評価指標について、以下の3つのケースに分けて解説します。
【A】各予測対象が「どのクラスに属するか」を予測するもの
【B】上記Aのうち、クラス間に順序関係があるもの
【C】各予測対象が「あるクラスに属する確率」を予測するもの
【A】「どのクラスに属するか」を予測する場合の評価指標
データに偏りが無いケース:正答率 (multi-class accuracy)
「どのクラスに属するか」を予測する場合の評価指標では、対象とするデータのクラス分布に偏りがあるか否かによって、使用に適した評価指標が異なります。
正答率 (multi-class accuracy) は、クラス分布に偏りが無いデータに適した評価指標です。多クラス分類における正答率は、二値分類タスクにおける正答率を多クラスに拡張したもので、全ての予測(全サンプル数)のうち、正しく予測されたサンプル数の割合によって表されます。
以下は、0~9の10区分のクラスに分類するタスクにおける混合行列です。混同行列は、予測値と実際の値との関係を以下のようなマトリクスとして表現したものです。
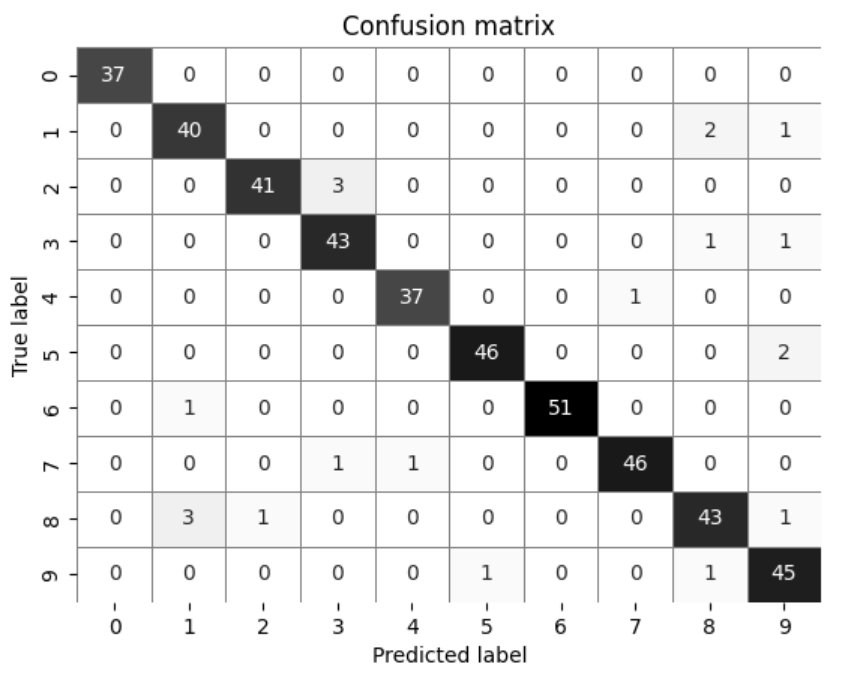
Muller, Guide(2017)をもとに、Intelligence In Society作成
縦軸が実際のクラス (True label)、横軸が予測したクラス (Predicted label) を表し、対角線上にある黒いマスは予測クラスと実際のクラスが一致している正しい予測の数、それ以外の白いマスは予測クラスと実際のクラスが一致していない誤った予測の数を表します。
ここでの正答率は、白マス(誤った予測)と黒マス(正しい予測)を合わせた全ての数の合計に占める、黒マスの合計の割合に当たり、実際に計算を行うと95.3%となります1。
データに偏りがあるケース:mean-F1, macro-F1, micro-F1
正答率はその分かりやすさが大きな強みである一方、クラス分類に偏りのある不均衡なデータにおいては不適切な評価指標となる可能性があります。上記の10クラス分類において、仮にクラス「0」が全体の9割を占めている場合、全てのサンプルを「0」と予測するモデルの正答率は90%となりますが、そのようなモデルには意味がありません。
二値分類タスクにおけるF1スコアを多クラス分類に拡張した、mean-F1, macro-F1, micro-F1は、不均衡なデータでの使用により適した評価指標です。これらの指標は、例えば以下のような、各サンプルが1つ以上のクラスに属する「マルチラベル分類」においても良く使用されます。
| サンプルNo | 実際の値 | 予測値 |
| 1 | 1, 2, 5 | 1, 3, 4 |
| 2 | 1, 4, 5 | 2, 5 |
| 3 | 3, 4 | 1, 3, 5 |
mean-F1
mean-F1は、サンプル単位で計算したF1スコアの平均値です。例えば上記のサンプルNo.1のF1スコアは、(TP=1, TN=0, FP=2, FN=2) で0.33となりますが、これを各サンプルについて算出し平均したものが、mean-F1スコアとなります。
実際に上記表のマルチラベル分類におけるmean-F1スコアを計算した結果は、0.377となります。
macro-F1
macro-F1は、クラス単位で計算したF1スコアの平均値です。例えば上記のクラス1のF1スコアは、(TP=1, TN=0, FP=1, FN=1) で0.5となりますが、これを各クラスについて算出し平均したものが、macro-F1スコアとなります。
上記表のマルチラベル分類におけるmacro-F1スコアは、0.388となります。なお、macro-F1と類似するものとして、各クラスの発生数に応じて重み付けした上で平均値を取る、weighted-F1スコアという指標も使用されます。
micro-F1
micro-F1は、サンプル×クラスの全てのペアについて、それぞれ個別に真陽性・真陰性・偽陽性・偽陰性を判別し、その混合行列に基づいて計算したF値です。
例えば上記表では、3つのサンプル×5クラスで15のペアがあり、全てを分類すると (TP=3, TN=2, FP=5, FN=5) となることから、この混合行列よりmicro-F1スコアが0.375と計算されます。( 2TP/(2TP + FP + FN) = 0.375 )
【B】クラス間に順序関係がある場合の評価指標
quadratic weighted kappa
年齢区分や年収区分、ECでの商品のレーティングなど、多クラス分類の中でも特にクラス間に順序関係がある場合に使用される評価指標が、quadratic weighted kappa (QWK) です。
quadratic weighted kappaは、クラス分類において2つの評価者による分類(実際の値と予測値など)の一致度の高さを評価するコーエンのカッパ係数 (Cohen’s kappa) に対して、「実際の値と予測値の差の二乗」を重みとして付与したものです。
ここで、poは実際の値と予測値の観測された一致率、peは仮に実際の値と予測値がともにランダムにクラス分類を行ったとした場合に期待される一致率を表します。コーエンのカッパ係数は、ランダムにクラス分類を行った場合の偶然の一致に比べて、実際の値と予測値の一致度がどのくらい高いかを評価していると理解できます。
quadratic weighted kappaは、このpoとpeに対して重み( =w ) として「実際の値と予測値の差の二乗」を与えたもので、例えば実際の値が「5」、予測値が「2」であった場合、重みは (5-2)^2 = 9となります。これにより、実際の値から大きく離れた予測値に対してペナルティを課しています。
全ての予測値が正しい場合のquadratic weighted kappaスコアは1、ランダムな予測値のスコアは0となります。
【C】「あるクラスに属する確率」を予測する場合の評価指標
logloss (multi-class logloss)
「あるクラスに属する確率」を予測する際の評価指標としてよく用いられるものが、logloss (multi-class logloss) です。
多クラス分類におけるloglossは、二値分類におけるloglossを多クラス分類に拡張したもので、実際の値に対する予測確率の対数を取り、符号を反転させたものを、全てのサンプルについて平均したものとして計算されます。
| 各クラスの予測確率 | |||||
| 実際の値 | 1 | 2 | 3 | 実際の値の予測確率p’i | -log(p’i) |
| 1 | 0.7 | 0.1 | 0.2 | 0.7 | 0.357 |
| 2 | 0.4 | 0.5 | 0.1 | 0.5 | 0.693 |
| 3 | 0.3 | 0.4 | 0.3 | 0.3 | 1.20 |
| 平均 |
logloss: |
||||
計算式では以下のように表されます。ここでM はクラス数、yi,m はサンプルi のクラスがm のときに1、それ以外で0を取る変数、pi,m はサンプルi のクラスがm である予測確率を表します。
loglossは0~ 無限大の値を取り、値が小さいほど、より正確な確率の予測を行っていると評価されます。上記の例から、サンプルの実際のクラスに対する確率を低く予測すると、大きなペナルティが与えられ、loglossが大きな値となることが分かります。
ここまで、「多クラス分類タスク」における代表的な評価指標について、その定義・計算方法や特徴を解説しました。
当記事に関連するトピックについての詳細は、以下のページをご覧ください。
また、機械学習・データ分析一般に関する全ての記事は以下のページからご覧いただけます。
参考文献:
◦scikit-learn “API Reference – sklearn.metrics – cohen_kappa_score” https://scikit-learn.org/stable/modules/generated/sklearn.metrics.cohen_kappa_score.html (2026年6月9日最終閲覧)
◦Andreas C. Muller、Sarah Guido (2017)『Pythonではじめる機械学習―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎』O’Reilly Japan
◦門脇大輔,阪田隆司,保坂桂佑,平松雄司 (2019)『Kaggleで勝つデータ分析の技術』, 技術評論社
◦Foster Provost, Tom Fawcett (2014) 『戦略的データサイエンス入門―ビジネスに活かすコンセプトとテクニック』O’Reilly Japan
注記:
1. Muller, Guide(2017)より引用















